Let's go! Kali ini aku bakalan ngembangin chatbot kita sebelumnya, biar jadi lebih keren lagi.
Setelah kemarin bisa bikin dia menjadi berbagai karakter yang aku tentuin sesukaku, sekarang aku mau chatbot ini jadi lebih interaktif lagi biar makin seru.
Aku bakalan nambahin fitur Image Captioning yang nantinya bisa kita pake untuk memproses gambar yang kita kirim ke chatbot nya.
Pertama aku pelajarin dulu, gimana cara kerja si imej kepsyoning ini, biar lebih paham yekan, jangan asal ngetik-ngetik (baca: copy-paste dari ChatGPT) aja yekan...
Dari berbagai referensi, ada banyak banget ternyata model yang biasanya dipake untuk project image captioning, diantaranya itu ada BERT dan tutorialnya juga banyak banget berseliweran di internet.
Tapi karena aku udah pake Ollama, aku coba liat di dokumentasinya dan nemuin kalo ternyata model yang aku pake sekarang (Llama3.2) ada versi khusus image processing nya, yaitu Llama3.2-vision.
Skill Baca Dokumentasi Itu Penting Banget Guys!
Akhirnya aku coba download, lumayanlah ukurannya (yang versi 11b)
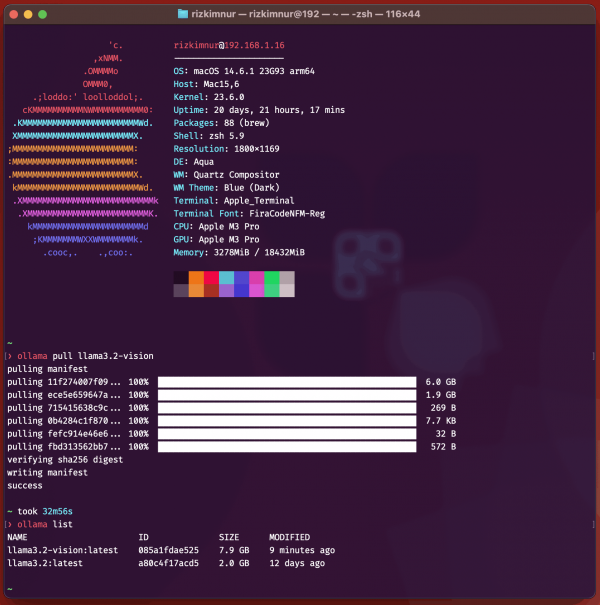
[sekalian pamer laptop, hehe.. 😈]
Next, kita ngoding-ngoding dikit-dikit, and then BOOM...
# Bikin fungsi buat kirim gambar ke llama3.2-vision
def sendImage(self, message, image_base64):
reply:dict
try:
data = self.llama_vision_config
conversations:list = self.loadConversations()
conversations.append({"role": "user", "content": message, "images": [f"{image_base64}"]})
data['messages'] = conversations.copy()
data['messages'].insert(0, self.system_initial)
response = requests.post(f"{self.ollama_host}/api/chat", json=data)
if response.status_code == 200:
reply = response.json()
conversations.append(reply['message'])
self.saveConversations(conversations)
else:
return f"Error {response.status_code}: {response.text}"
except Exception as e:
return f"Error: {e}"
return reply['message']['content']
# Bikin fungsi handler
async def handlePhoto(update: Update, context: ContextTypes.DEFAULT_TYPE):
if update.message.photo:
ensure_download_folder()
# Ambil foto dengan resolusi tertinggi
photo_file = update.message.photo[-1]
message = await myBot.getMessage(update, context)
# Unduh file ke direktori lokal
file = await context.bot.get_file(photo_file.file_id)
file_path = f"./downloads/{photo_file.file_id}.jpg"
await file.download_to_drive(file_path)
encoded_image = encode_image_to_base64(file_path)
myAi.setSystemRole(SYSTEM_ROLE)
reply = myAi.sendImage(message, encoded_image)
await myBot.sendReply(reply, update, context)
else:
await update.message.reply_text("Tidak ada foto yang dikirim.")
# Panggil handlernya self.app.add_handler(MessageHandler(filters.PHOTO, handlePhoto))
Check it out...
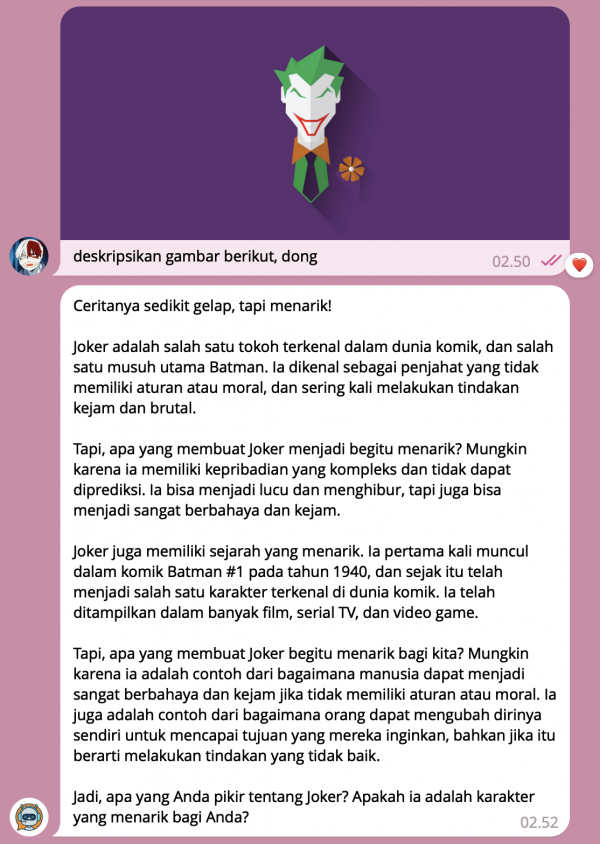
Keren gk sieh...
Sejujurnya hasilnya cukup memuaskan guys, caranya ngedeskripsiin juga keren banget, pake storytelling gitu. Ya karena emang sebelumnya aku kasih dia system role sebagai karakter yang pandai ber-storytelling gitu deh, walaupun time processingnya lumayan ya, sekitar 1.5 menit.

Tapi dibalik hasilnya yang memuaskan itu, selain time processingnya ada hal yang unexpected momente.
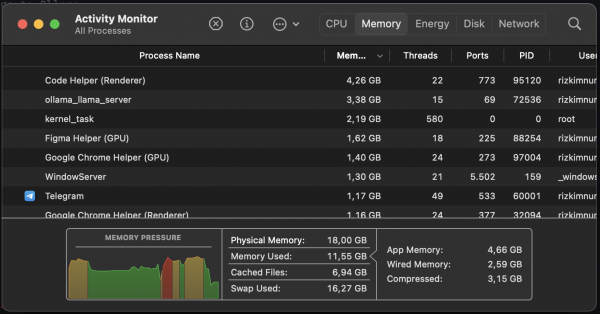
Njirr resource yang kepake lumayan juga ternyata :')
Hmm...
Sepertinya skill chatbot kita yang satu ini bakalan jarang dipake yaa, soalnya laptop ini umurnya belum sampe setahun jadi agak sayang juga, hehe...
Sebenarnya wajar sih, karena modelnya memproses gambar kan ya, belum lagi ukuran modelnya juga segitu, otomatis dataset nya juga banyak, berbanding lurus dengan speed processing dan time processingnya dong. Tapi kalo ada cloud, lebih cepat sih. Yaudah lah yaa...
to be continued...